What problem does the algorithm solve?
What is a binary search algorithm? It allows you to search for things incredibly quickly! It’s simple really, when you need to find something in a massive list or collection of data, you can use a binary search algorithm to find it.
How does it work?
The algorithm is kind of similar in concept to what we would call binary search trees, which are an incredibly popular way to organise file-systems and databases to allow for fast lookup/search of data.
All modern filesystems for operating-systems use an adaption of a binary-tree style of organising data, usually called a B-tree. This includes Microsoft Window’s NTFS, MacOS APFS/HFS+ and Linux’s Ext4/Btrfs/ZFS, all of which minus NTFS have incredibly fast indexing and lookup for searching files. [1]
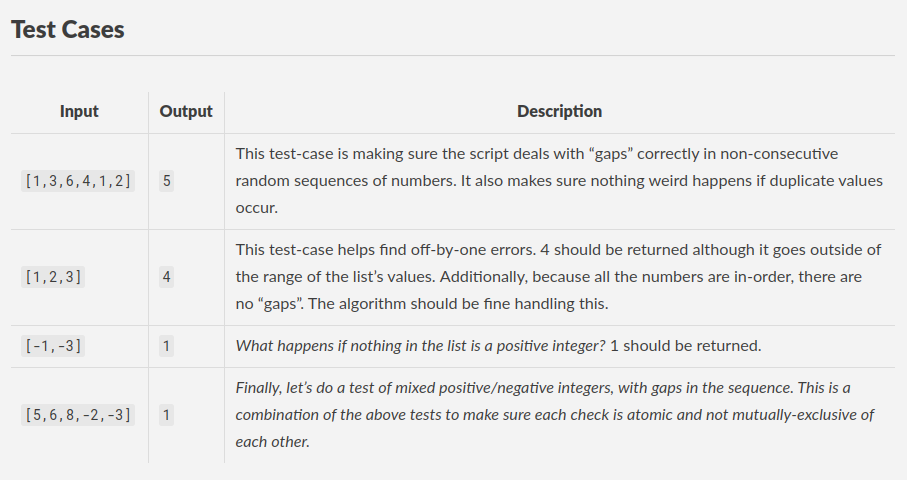
In a binary search tree, you look at the root node and do a comparison. Is my object (Could be pretty much any data, a string, an integer, an executable’s hash, whatever!) smaller or larger in value than the root? If smaller, you typically go to the left side and if larger, you typically go to the right side.
The tree is organised, sorted, in a way such that if you follow this simple check over and over, you will find the item you’re looking for. [8]

The correct item is found after three comparisons within a collection of nine items, which means we’ve found

The correct item is found after three comparisons within a collection of nine items, which means we’ve found our item in nearly exactly log2(n) comparisons log2(9) = ~3.17.
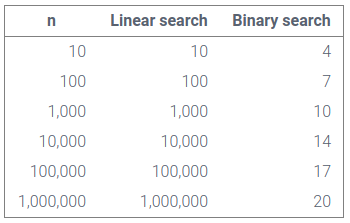
In fact, this is just a tiny bit “better” than the actual worst-case possible scenario for this algorithm, which happens to be log2(n) + 1. Using this, we can find out that the maximum number of comparisons with nine items is log2(9) = ~4.17, but for general trends we should always drop constants so our Big-O notation ends up as log2(n).

A binary search tree is pretty much what a binary search algorithm does, though, in essence. You must start with sorted data, but then you find the midpoint (The middle value), do your comparison and follow it along, almost exactly like the binary search tree!
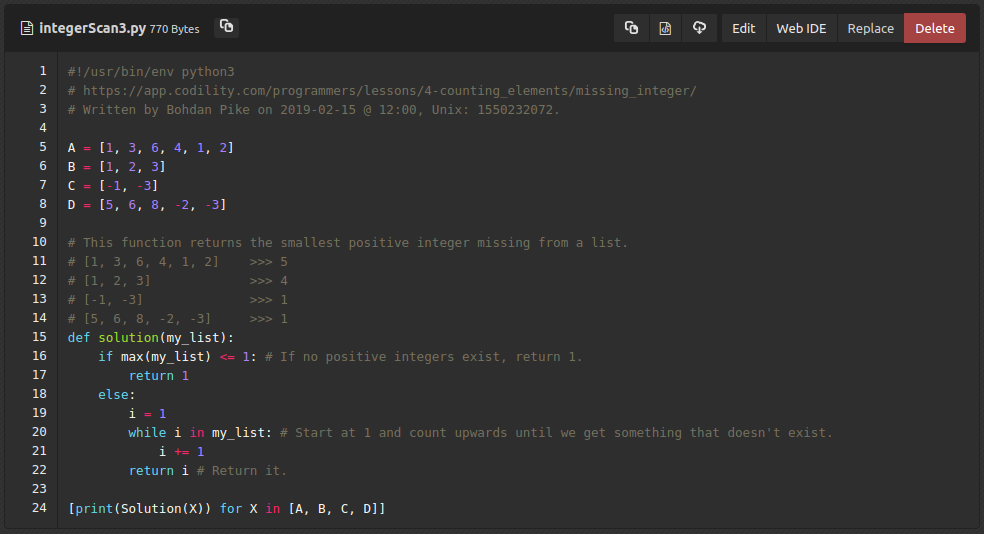
Let’s have a look at some Python code:
def b(A,k):
l,h=0,len(A)
while l<h:
m=(l+h)//2
if A[m]>k:h=m
elif A[m]<k:l=m+1
else:return m
return -1
(Code sourced from https://codegolf.stackexchange.com/questions/63726/iterative-binary-search/63727 modifications had to be made since in Python 3, a floored division is required // instead of / otherwise you’ll get an error like below.)
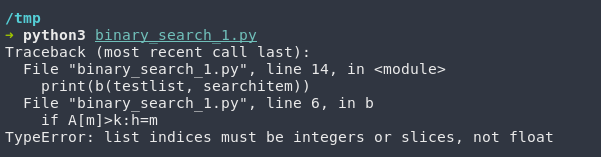
Uh… Okay. That’s a little hard to decipher. Let’s try… Hm. That’s also not that easy to understand. This is unfortunately an algorithm that’s incredibly hard to write correctly since you need to be very careful about off-by-one errors and make sure your while loop exits correctly. [2] [3]
Essentially what this algorithm is doing, for each sequence presented, it splits it at the midpoint and checks if the midpoint is smaller than the current item that’s being searched. It then adjusts the outer boundaries of the list using the first/last pointers and repeats over and over until it is finished. [7]
def binarySearch(alist, item):
first = 0
last = len(alist)-1
found = False
while first<=last and not found:
midpoint = (first + last)//2
if alist[midpoint] == item:
found = True
else:
if item < alist[midpoint]:
last = midpoint-1
else:
first = midpoint+1
return found
Static/Dynamic Analysis
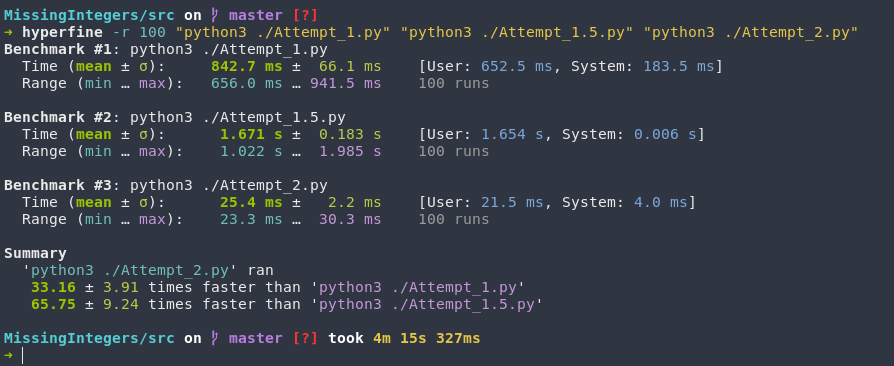
Using [4] and tweaking it slightly, I was able to do a running-time analysis of the two most common searching algorithms, linear & binary. (Python already has a linear search algorithm implemented with the in builtin.)
I collected the data and then plotted it to show the general trend.
#!/usr/bin/env python3
import time
# Change this from 10^0 to 10^8
range_limit = 1000000000
x = [x for x in range(range_limit)]
def Time_linear(alist,item):
t1 = time.time()
found = item in alist
t2 = time.time()
timer = t2 - t1
return timer
def Time_binarySearch(alist, item):
first = 0
last = len(alist)-1
found = False
t1 = time.time()
while first<=last and not found:
midpoint = (first + last)//2
if alist[midpoint] == item:
found = True
else:
if item < alist[midpoint]:
last = midpoint-1
else:
first = midpoint+1
t2 = time.time()
timer = t2 - t1
return timer
print(f"binarySearch: {Time_binarySearch(x, range_limit//2)}")
print(f"linearSearch: {Time_linear(x, range_limit//2)")
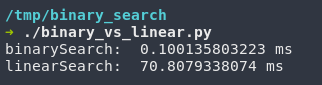
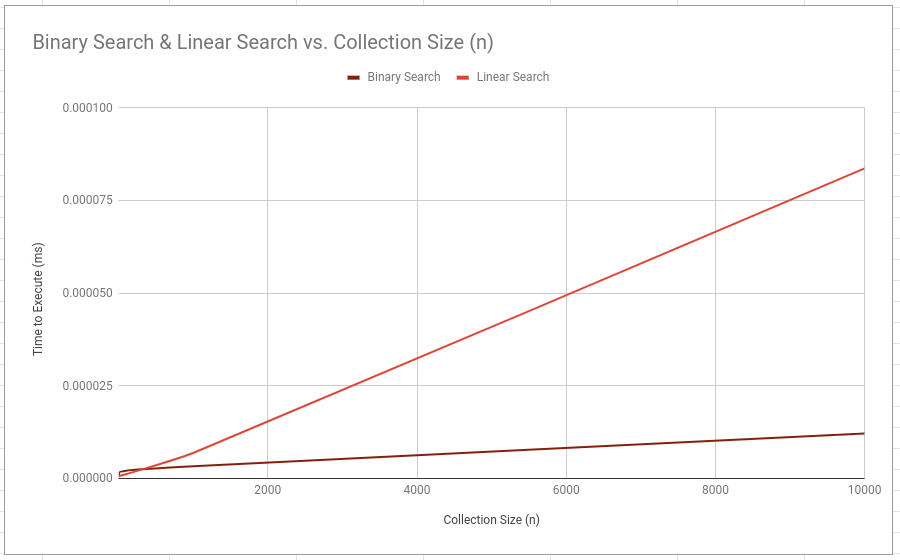
This makes a lot of sense if we look at our algorithm and attempt a static analysis! Our collection-size is going to be our limiting input. For each item in n, we want to divide it into 2, n/2 and then do it over and over and over again. This gives us n/2^x = 1 which can be rearranged into n = 2^x. We can remove the exponent by using a logarithm instead which leaves us with log2(n), which happens to be the known worst-case performance.
If we look at the root node, and our item happens to match, we have a single sub-problem of size 1, nothing else happens since we’ve already found our item and we finish with a performance of O(1). This happens to be the best-case performance. [5]

Proof of Termination
while first<=last and not found:
midpoint = (first + last)//2
if alist[midpoint] == item:
found = True
else:
if item < alist[midpoint]:
last = midpoint-1
else:
first = midpoint+1
===== Simplify =====
while first<=last:
if CONDITION:
last = midpoint-1
else:
first = midpoint+1
# Assuming a sequence that is in order, the while loop *must* end because either branch make the first + last variables closer and closer until one surpasses the other.
This causes `first !<= last` and the while loop ends.
Preconditions
- A list/sequence must be supplied, as well as an item to look up. Usually an integer.
- The list/sequence MUST be sorted for the algorithm to work.
Invariants:
– The value I am looking for is always within the current split section or “sub-problem”, if it exists.
References
[1] Comer, D. (June 1979). “The Ubiquitous B-Tree”. Computing Surveys. https://en.wikipedia.org/wiki/B-tree
[2] TFeld (November 2015) Stack Overflow, Code Golf https://codegolf.stackexchange.com/questions/63726/iterative-binary-search/63727
[3] Miller, B., Ranum, D. (2014). “
Problem Solving with Algorithms and Data Structures” Interactive Python https://interactivepython.org/runestone/static/pythonds/SortSearch/TheBinarySearch.html
[4] Gospodinov, N. (August 2015) Stack Overflow https://stackoverflow.com/questions/31936657/binarysearch-vs-in-unexpected-results-python
[5] Kay, A. (May 2018) “Static Analysis” DS&A Data Structures and Algorithms https://dsaa.werp.site/post/static-analysis/
[6] 2cupsOfTech, (October 2012) Stack Overflow https://stackoverflow.com/questions/2307283/what-does-olog-n-mean-exactly/13093274#13093274
[7] Khan Academy (n.d.), “Binary search” Computer Science Courses https://www.khanacademy.org/computing/computer-science/algorithms/binary-search/a/binary-search
[8] Javatpoint (n.d.), “Searching in Binary Search Tree” https://www.javatpoint.com/searching-in-binary-search-tree









{kind=link}
{kind=link}